
Простенькая программа для исследования будет :
- for(int k = 0; k < 100; ++k) {
- fRes = fNum1/fNum2;
- sqrtRes = std::sqrt( radicand );
- res = k % module;
- fNum1 += 0.01;
- fNum2 -= 0.01;
- radicand += 0.1;
- }
- fNum1 = .0f;
- fNum2 = 1.1f;
- radicand = .0f;
- } //while(1)
rts2800_fpu32.lib
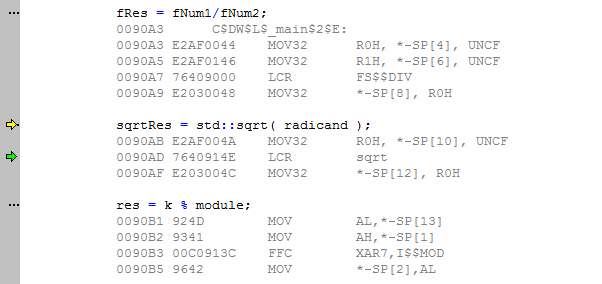
Результаты профилирования кода, созданного при помощи rts2800_fpu32.lib:
Mixed code:
Примечание! см. TMS320C28x CPU and Instruction Set Reference Guide Table 6-2
LCR 22bitAddr Long call using RPC
FFC XAR7,22bitAddr Fast function call
Вывод: деление - самая тяжеловесная операция. Занимает 227 тактов процессора. Посмотреть что означают колонки таблицы можно здесь
rts2800_fpu32_fast_supplement.lib
Сперва ознакомиться со статьей увеличиваем производительность стандартных функций заменой rts2800_fpu32 на rts2800_fpu32_fast_supplement .
Результаты профилирования кода, созданного при помощи rts2800_fpu32_fast_supplement.lib

Вывод: теперь деление не самая “тяжелая” операция, напротив - самая быстрая! Всего 20 тактов процессора!!! Извлечение корня - 24 такта!
В дополнение приведу данные из документации на Fast RTS библиотеку:

Комментариев нет:
Отправить комментарий